
Don’t use STL regex library in Microsoft Visual C++ (MSVC), at least for now
I’ve been working on the new research projects for several days. The first task is pretty simple: load some datasets in UCR Time Series Archive into memory.
In our previous papers1,2, since the original authors’ algorithms were done in Java (FastDTW3, TEASER4, etc.), I’ve mainly written Java for related experiments. I haven’t touched C++ for a while, so this time I decided to use C++, but I never expected to pay the “price” for my choice.
How could it go wrong with \t+?
The file format of UCR Time Series Archive is pretty straightforward: n rows of time series in each dataset, and for each time series, there are m columns separated by TAB (\t), representing m datapoints.
C++ <string> library didn’t come with a built-in splitting function, and I don’t really want to use 3rd-party libraries (like boost::split) in my little project. It could be very painful to use external libraries in C++, and when it comes to compatibility issues, oh man good luck to you.
I know I could make it with string::find, but hey it’s year 2021, C++ 20 was finalized last September, and I believe there must be fancier way than tedious string::find, so I came up with an idea: searching “How to split string in modern C++” on Stack Overflow.
And I did get a hit: Split a string using C++ 11, a question asked 9 years ago. The most voted answer showed an “elegant” way using std::regex_token_iterator.
So I wrote down this piece of code in Visual Studio 2019 (MSVC v14.28.29333, the latest version at the time of writing):
typedef std::vector<std::pair<int, std::vector<double>>> TimeSeriesDataset;
TimeSeriesDataset readTSV(const std::string& tsvPath) {
TimeSeriesDataset dataset;
std::ifstream stream{ tsvPath };
std::string line;
static const std::regex split(R"(\t+)");
while (std::getline(stream, line)) {
std::cregex_token_iterator first{ line.data(), line.data() + line.length(), split, -1 }, last;
int label;
std::from_chars(first->first, first->second, label);
std::vector<double> datapoints;
std::transform(++first, last, std::back_inserter(datapoints), [](auto subMatch) {
double value;
std::from_chars(subMatch.first, subMatch.second, value);
return value;
});
dataset.push_back(std::make_pair(label, datapoints));
}
return dataset;
}
Note that I wrote a regular expression of \t+. The + sign is in fact not necessary in my case, but at that time I didn’t think too much about this simple expression. Consider the DFA only contains two states:
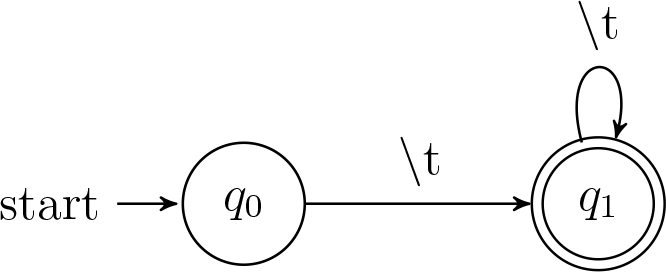
How could it possibly go wrong?
Bad <regex> implementation in MSVC
++regex_token_iterator takes too long
When I hit F5 to launch the program, I immediately noticed there is something wrong: it took way too long to load Mallat_TEST.tsv. I won’t consider this file to be big: essentially a 2345 x 1025 matrix of decimal, and my past experience in Java showed that a second should be long enough to load this file.
So I started the performance profiler to see what happened. To my surprise, it takes 6 full minutes (under Debug (Win32) configuration) to finish running the program on Mallat_TEST.tsv.
The hot path analysis reveals which operations hold the most CPU time (click picture to enlarge):
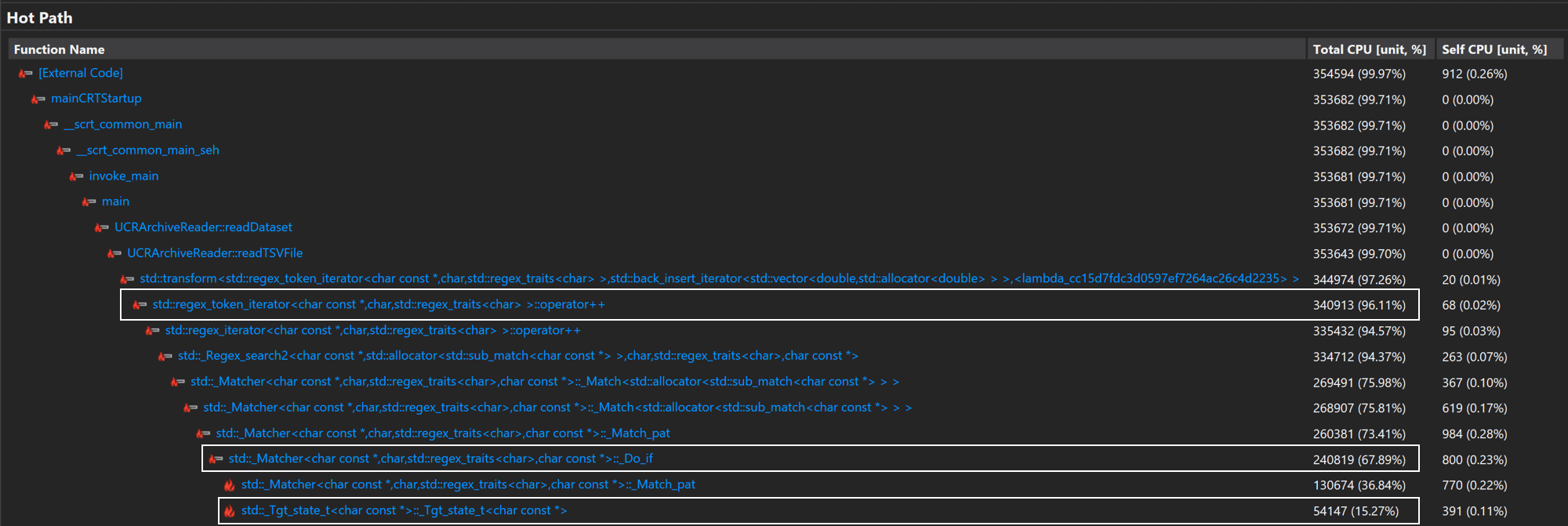
Apparently most of the time was spent in std::transform, which implicitly refers to std::regex_token_iterator::operator++.
Following the call tree reveals creating, deleting, and assigning object std::_Tgt_state_t in function std::_Matcher::_Do_if caused the problem:
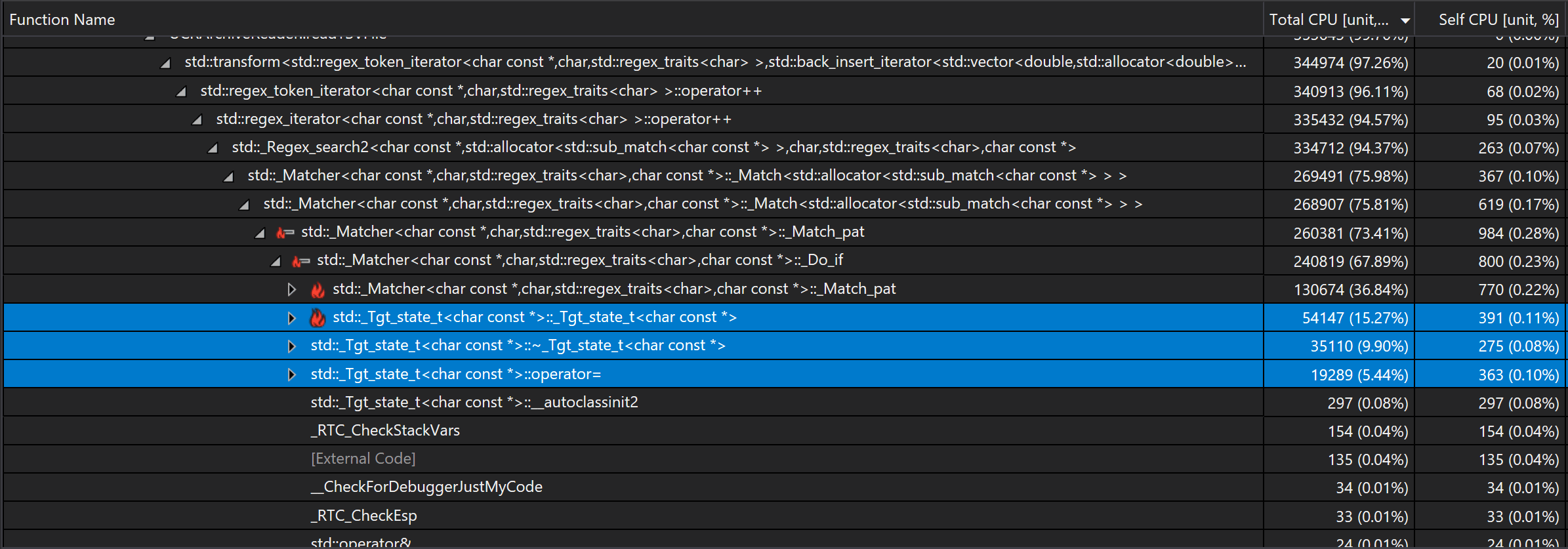
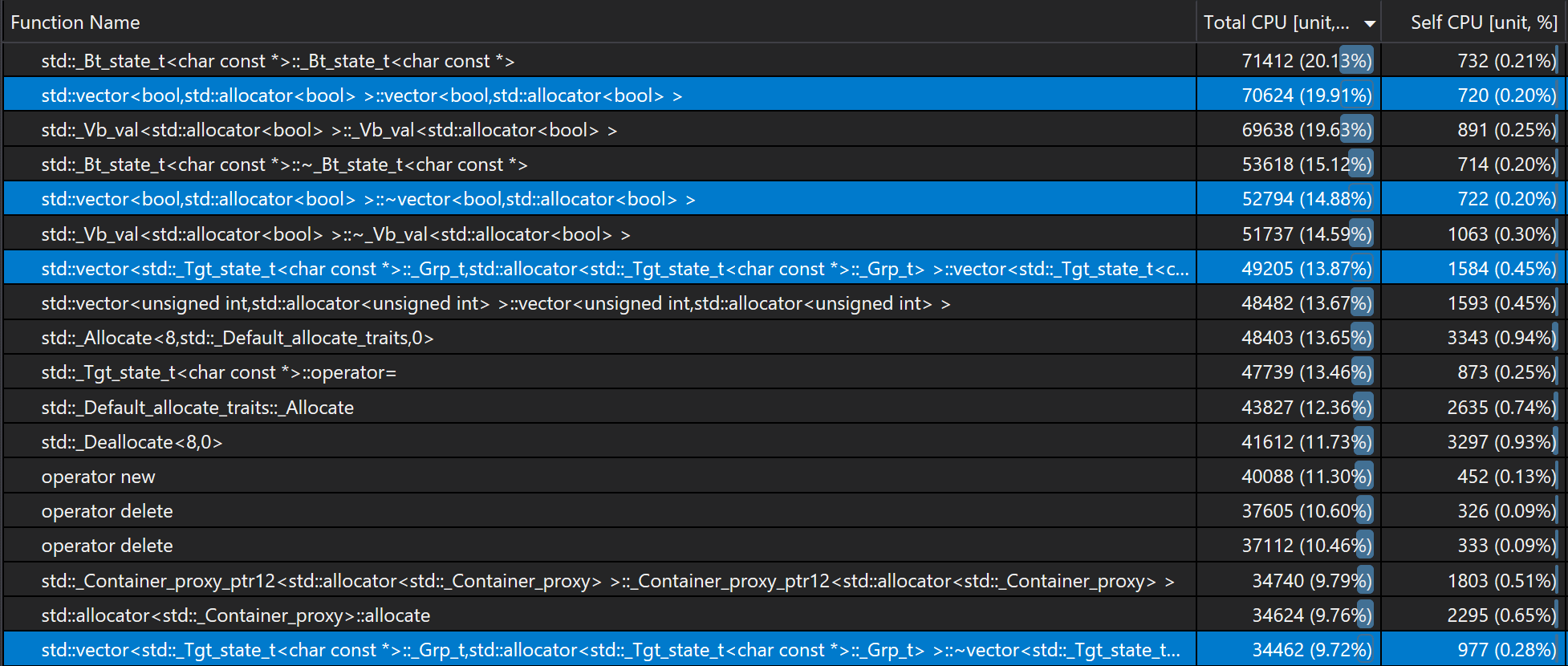
Also if we sort used CPU time by functions, it reveals the same issue:
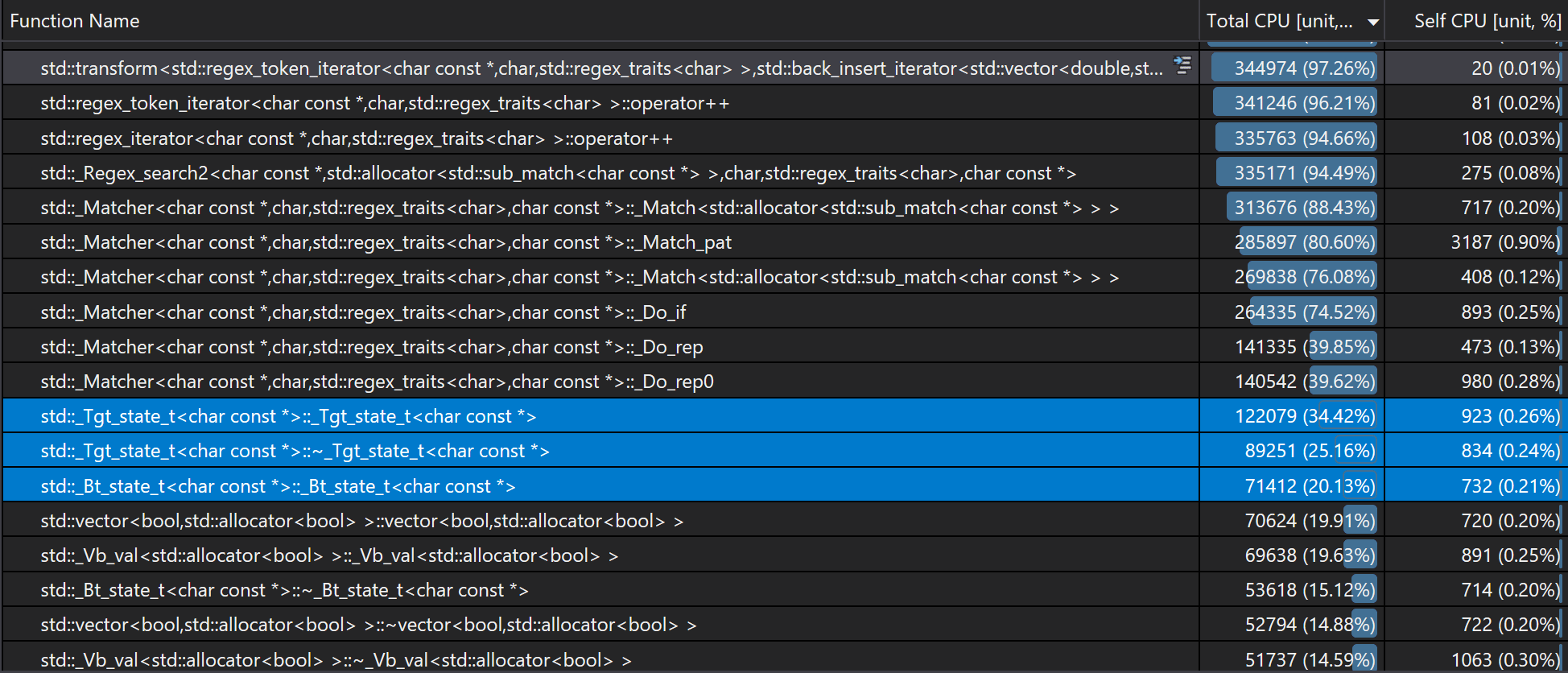
This means there must be something wrong with std::_Tgt_state_t.
What indeed happened?
So I looked into <regex>’s source code for _Matcher::_Do_if. The first glance looks pretty normal:
// IMPLEMENTATION OF _Matcher
template <class _BidIt, class _Elem, class _RxTraits, class _It>
bool _Matcher<_BidIt, _Elem, _RxTraits, _It>::_Do_if(_Node_if* _Node) { // apply if node
_Tgt_state_t<_It> _St = _Tgt_state;
// look for the first match
for (; _Node; _Node = _Node->_Child) { // process one branch of if
_Tgt_state = _St; // rewind to where the alternation starts in input
if (_Match_pat(_Node->_Next)) { // try to match this branch
break;
}
}
// if none of the if branches matched, fail to match
if (!_Node) {
return false;
}
// if we aren't looking for the longest match, that's it
if (!_Longest) {
return true;
}
// see if there is a longer match
_Tgt_state_t<_It> _Final = _Tgt_state;
auto _Final_len = _STD distance(_St._Cur, _Tgt_state._Cur);
for (;;) { // process one branch of if
_Node = _Node->_Child;
if (!_Node) {
break;
}
_Tgt_state = _St;
if (_Match_pat(_Node->_Next)) { // record match if it is longer
const auto _Len = _STD distance(_St._Cur, _Tgt_state._Cur);
if (_Final_len < _Len) { // memorize longest so far
_Final = _Tgt_state;
_Final_len = _Len;
}
}
}
// set the input end to the longest match
_Tgt_state = _Final;
return true;
}
The variable _Tgt_state is a member of class _Matcher.
However, if we take a closer look on how _Tgt_state is assigned and other temporary _Tgt_state_t variables _St and _Final are constructed:
_Tgt_state_t<_It> _St = _Tgt_state;
_Tgt_state = _St;
_Tgt_state_t<_It> _Final = _Tgt_state;
_Final = _Tgt_state;
_Tgt_state = _Final;
All these assignments are implicitly invoking operator=, and the default operator= performs a member-wise copy, which could lead to deep copy if there are STL containers without special handling mechanism.
A later look at the definition of _Tgt_state_t proves my thought:
// CLASS TEMPLATE _Bt_state_t
template <class _BidIt>
class _Bt_state_t { // holds the state needed for backtracking
public:
_BidIt _Cur;
vector<bool> _Grp_valid;
};
// CLASS TEMPLATE _Tgt_state_t
template <class _BidIt>
class _Tgt_state_t : public _Bt_state_t<_BidIt> { // holds the current state of the match
public:
struct _Grp_t { // stores a pair of iterators
_BidIt _Begin;
_BidIt _End;
};
vector<_Grp_t> _Grps;
void operator=(const _Bt_state_t<_BidIt>& _Other) {
static_cast<_Bt_state_t<_BidIt>&>(*this) = _Other;
}
};
Class _Tgt_state_t has two member variables: _Grps and _Grp_valid (inherited from _Bt_state_t). Both of them are STL container vector, and by default, performing operator= over vector incurs deep copy.
Deep copy is already evil. To make it worse, the hot path reveals _Do_if would be called recursively (_Match_pat calls _Do_if and _Do_if calls _Match_pat). This means _Tgt_state_t variable _St and _Final are created and deleted every single time when _Do_if is called.
Remember class _Tgt_state_t has two vector member variables, and by default vector requires memory allocation/deallocation on heap. Normally this overhead seems neglectable, but under the circumstance of recursion, it could be a problem. The CPU time used by vector constructor/deconstructor proves:
So how can it be fixed? Well, in the very beginning, I thought how hard could it be? But after all the deep digging into source code, it could be very hard and might require a complete refactoring.
Speed under Release configuration
I decided to give MSVC one more chance, by compiling the code under Release configuration, or more precisely, with compiling options /O2 (maximum optimizations, favor speed) and /Ob2 (inline expansion level 2).
I wrote a small snippet to measure how long my readTSV function takes:
auto start = std::chrono::steady_clock::now();
auto dataset = readTSV(R"(../UCRArchive_2018/Mallat/Mallat_TEST.tsv)");
auto end = std::chrono::steady_clock::now();
std::cout << "Mallat_TEST[0], label: " << dataset.front().first << ", data[0, last]: "
<< dataset.front().second.front() << ", " << dataset.front().second.back() << std::endl;
std::cout << "Mallat_TEST[last], label: " << dataset.back().first << ", data[0, last]: "
<< dataset.back().second.front() << ", " << dataset.back().second.back() << std::endl;
std::cout << "Elapsed: "
<< std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count()
<< " ms" << std::endl;
The reason I added two more lines output is to avoid compiler’s optimization over potential dead code (clang does very well in this kind of elimination), which may remove the invocation to readTSV.
Now I can compile this little program:
# /nologo: Suppress copyright message
# /TP: Treat all files as C++
# /W3: Warning level 3
# /GR: Enable C++ RTTI
# /EHsc: Enable C++ EH
# /MD: Link with MSVCRT.LIB
# /O2: Maximum optimizations (favor speed)
# /Ob2: Inline expansion level 2
# /NDEBUG: Define NDEBUG marco
# /std:c++17: C++ 17 stardard
cl /nologo /TP /W3 /GR /EHsc /MD /O2 /Ob2 /DNDEBUG /std:c++17 RegexTokenIterator_C++17.cpp
Yet it still took 31.4 seconds to load Mallat_TEST.tsv:
# MSVC v14.28.29333 (/O2 /Ob2) with \t+
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 31461 ms
How about plain \t
I also tried the simplest regex for this case: \t. With the same compiler options, it still takes 4.6 seconds:
# MSVC v14.28.29333 (/O2 /Ob2) with \t
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 4641 ms
which is way less desirable and 5x slower than expected.
What about clang and gcc?
clang 11.0.1 + libc++ 11.0
When I first tried to compile with:
clang++ -O3 -std=c++17 -stdlib=libc++ RegexTokenIterator_C++17.cpp -o clangRTI
clang spits out an error:
RegexTokenIterator_C++17.cpp:34:4: error: call to deleted function 'from_chars'
std::from_chars(subMatch.first, subMatch.second, value);
^~~~~~~~~~~~~~~
/usr/local/clang-11.0.1/bin/../include/c++/v1/algorithm:1948:21: note: in instantiation of function template specialization 'readTSV(const std::string &)::(anonymous class)::operator()<std::__1::sub_match<const char *>>' requested here
*__result = __op(*__first);
^
RegexTokenIterator_C++17.cpp:32:8: note: in instantiation of function template specialization 'std::__1::transform<std::__1::regex_token_iterator<const char *, char, std::__1::regex_traits<char>>, std::__1::back_insert_iterator<std::__1::vector<double, std::__1::allocator<double>>>, (lambda at RegexTokenIterator_C++17.cpp:32:65)>' requested here
std::transform(++first, last, std::back_inserter(datapoints), [](auto subMatch) {
^
/usr/local/clang-11.0.1/bin/../include/c++/v1/charconv:123:6: note: candidate function has been explicitly deleted
void from_chars(const char*, const char*, bool, int = 10) = delete;
^
/usr/local/clang-11.0.1/bin/../include/c++/v1/charconv:606:1: note: candidate template ignored: requirement 'is_integral<double>::value' was not satisfied [with _Tp = double]
from_chars(const char* __first, const char* __last, _Tp& __value)
^
/usr/local/clang-11.0.1/bin/../include/c++/v1/charconv:613:1: note: candidate function template not viable: requires 4 arguments, but 3 were provided
from_chars(const char* __first, const char* __last, _Tp& __value, int __base)
^
1 error generated.
I was confused and “What?” is my first reaction. So I digged into libc++’s <charconv> and the only 3 definitions of std::from_chars I found are:
void from_chars(const char*, const char*, bool, int = 10) = delete;
template <typename _Tp, typename enable_if<is_integral<_Tp>::value, int>::type = 0>
inline _LIBCPP_INLINE_VISIBILITY from_chars_result
from_chars(const char* __first, const char* __last, _Tp& __value)
{
return __from_chars_atoi(__first, __last, __value);
}
template <typename _Tp, typename enable_if<is_integral<_Tp>::value, int>::type = 0>
inline _LIBCPP_INLINE_VISIBILITY from_chars_result
from_chars(const char* __first, const char* __last, _Tp& __value, int __base)
{
_LIBCPP_ASSERT(2 <= __base && __base <= 36, "base not in [2, 36]");
return __from_chars_integral(__first, __last, __value, __base);
}
Meh. This means at the time of writing, libc++ doesn’t support floating point numbers in std::from_chars.
So I had to replace the std::from_chars in the std::transform lambda with the old school strtod, and it worked.
The result is much better than MSVC’s, but still slow:
# clang 11.0.1 (-O3) + libc++ 11.0 with \t+
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 3017 ms
# clang 11.0.1 (-O3) + libc++ 11.0 with \t
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 1848 ms
gcc 5.5.0 + libstdc++ 3.4.21
I could have use the latest gcc 10.2, but I am just too lazy to compile it.
Fortunately gcc 5.5.0 + libstdc++ 3.4.21 has already fully supported C++ 14 features, so at least I can continue my experiments by simply replacing the last C++ 17 existence of std::from_chars to atoi.
The complier options are:
g++ -O3 -std=c++14 RegexTokenIterator_C++14.cpp -o g++RTI
I’m a little bit amazed by the result:
# gcc 5.5.0 (-O3) + libstdc++ 3.4.21 with \t+
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 992 ms
# gcc 5.5.0 (-O3) + libstdc++ 3.4.21 with \t
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 952 ms
Because both MSVC and clang + libc++ are in their latest stable version. For gcc + libstdc++, I was using an old version built on Oct. 2017, which I’d say it’s kind of unfair, but gcc + libstdc++ managed to win the game.
Tedious string::find did the trick
Nevertheless, I went back to the tedious way of string::find (let us also forget about whatever std::from_chars is):
typedef std::vector<std::pair<int, std::vector<double>>> TimeSeriesDataset;
TimeSeriesDataset readTSV(const std::string& tsvPath) {
TimeSeriesDataset dataset;
std::ifstream stream{ tsvPath };
std::string line;
while (std::getline(stream, line)) {
auto tabPos = line.find('\t');
auto label = atoi(line.data());
std::vector<double> datapoints;
for (size_t nextTabPos;
std::string::npos != (nextTabPos = line.find('\t', tabPos + 1));
tabPos = nextTabPos) {
datapoints.push_back(strtod(line.data() + tabPos + 1, nullptr));
}
datapoints.push_back(strtod(line.data() + tabPos + 1, nullptr));
dataset.push_back(std::make_pair(label, datapoints));
}
return dataset;
}
I’m not surprised to see this piece of code is way more faster than its regular expression equivalent under all three libraries:
# MSVC v14.28.29333 (/O2 /Ob2)
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 892 ms
# clang 11.0.1 (-O3) + libc++ 11.0
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 431 ms
# gcc 5.5.0 (-O3) + libstdc++ 3.4.21
Mallat_TEST[0], label: 5, data[0, last]: -1.06862, -1.01192
Mallat_TEST[last], label: 8, data[0, last]: -0.949403, -0.970955
Elapsed: 294 ms
Final speed comparison
With all the experiment data collected, we can finally compare the performance:
| Compiler (Options) | Time (ms) ( rti^ with \t+) | Time (ms) ( rti^ with \t) | Time (ms) ( string::find) |
|---|---|---|---|
MSVC v14.28.29333 (/O2 /Ob2) | 31461 | 4641 | 892 |
clang 11.0.1 (-O3)libc++ 11.0 | 3017 | 1848 | 431 |
gcc 5.5.0 (-O3)libstdc++ 3.4.21 | 992 | 952 | 294 |
^ rti is std::regex_token_iterator.
The result shows that at least for <regex>, libstdc++’s implementation is so far the best among all three libraries. But it still can’t beat the plain and tedious string::find, in terms of string splitting.
I tried to figure out why <regex> has been introduced for a decade and yet still so slow and badly implemented. A thread on Reddit points out something about ABI compatibility:
The fast engines add a zillion special cases for common patterns their engines recognize. But we can’t ever do that. And given that our engines were somewhat stupid initially now we can’t replace the engine with something better because that breaks ABI.
BillyONeal — std::regex_replace/std::chrono::high_resolution_clock::now() speed
Well, good luck to all of us C++ users.
Conclusion
It’s great to see the C++ standard getting periodical updates every 3 years since 2011: new STL components, syntax sugars, and a lot of other stuffs (range-based for loops, auto type deduction, variadic template (or parameter pack), and concepts finally, etc.) — all of which I (and probably many other people) have been waiting for years.
However, <regex> library is unfortunately an exception: apparently there is something wrong with MSVC’s underlying implementations, and the performance is surprisingly bad. Also not to mention <regex> library was introduced in C++ 11 since 2011 — a decade ago.
The lesson I learnt is that for simple tasks like splitting strings, it might be better just to stick with simple tools (string::find in this case, even though I have to reinvent the wheels every single time), instead of using something “fancy” like std::regex_token_iterator, at least for now.
Actually this is NOT the first time that I found issues in the particular STL implementation: several years ago, I noticed that the order of items from std::make_heap is slightly different between MSVC’s and GCC’s (or libstdc++). My later digging into source code revealed it was caused by the default comparison function: one used < and the other used <=.
Another issue is that specific feature mights not be fully implemented. Besides aforementioned libc++’s std::from_chars lacking support on floating point numbers, when I was trying to compile the cppwin32 project with Visual Studio 2017 (MSVC v14.16.27023), I found that MSVC’s std::to_chars has no support on floating-point in terms of std::chars_format::hex5. This made me upgrade to Visual Studio 2019.
All these chaos remind me the famous Russian proverb my advisor Dr. Keogh ever cited: “Доверя́й, но проверя́й” or “Trust, but verify”. Even standards like STL are not exceptions.
My experiences in C++ in the past decade has taught me one thing:
- C++ is very hard, and to make it correct is even harder.
References
-
R. Wu and E.J. Keogh, “FastDTW is approximate and Generally Slower than the Algorithm it Approximates,” IEEE Transactions on Knowledge and Data Engineering (TKDE), in press, 2020. ↩
-
R. Wu, A. Der, and E.J. Keogh, “When is Early Classification of Time Series Meaningful?,” arXiv, preprint, 2021. ↩
-
S. Salvador and P. Chan, “FastDTW: Toward Accurate Dynamic Time Warping in Linear Time and Space,” Intelligent Data Analysis, vol. 11, no. 5, 2007, pp. 561-580. ↩
-
Microsoft, Microsoft C++ language conformance table: charconv. ↩
Comments Go back to the top